Open Sourcing (Most Of) My Homelab Code
I'm a firm believer in managing infrastructure through code, and I make no exceptions for my homelab. Almost everything I run at home is managed with Kubernetes, Ansible, or Terraform (or some combination of the three), and I keep all the relevant code in a monorepo so it's easy to keep track of.
I've been meaning for a while to open source all the non-sensitive code I can (with inspiration from @ironicbadger), but using a monorepo made that a bit tricky—I had a bunch of GPG-encrypted secrets and network details in the repo that I didn't feel great about releasing to the public (even though I basically trust my encryption scheme). I couldn't find a great solution for publishing selected parts of the repo, so I went for a semi-nuclear option:
- Move everything sensitive to private git submodules (I don't love submodules but they work well enough for this sort of thing)
- Erase the git history and start from scratch!
The result is here; it's MIT licensed so feel free to poach anything that looks useful.
A Brief History of My Homelab
My homelab has been through a few iterations, and I've enjoyed exploring the pros and cons of different approaches to running software at home. I can't release the whole git history but I thought I'd use this opportunity to offer a brief tour through time (as best as I can remember it).
V1: NixOS and NixOps
Like many homelab journeys, mine began with a NAS. It was an old HP ProLiant hand-me-down, but enough to get started with! I added a few hard drives, loaded it up with NixOS (which I was running on my laptop at the time) and remotely managed it through NixOps.
If you're not familiar with NixOS, I'd definitely recommend checking it out. It's an operating system that's designed from the ground up to be "functional", meaning that the entire state of the system is deterministically defined through code. Two NixOS computers with the same Nix configuration should theoretically have the same exact system software and settings files down to the bit (even if the binaries were compiled on different machines).
NixOS is a huge step up in abstraction from configuration managers like Ansible, which try to guarantee certain things about a system (like "SSH is installed") but don't really go beyond that. It's also a step up from Terraform, which tends to rely on downstream APIs to "do the right thing" when it comes to idempotence and reproducibility (with varying results).
I greatly enjoyed tinkering with NixOS, but my eventual takeaway was that NixOS is the operating system of the future and it's going to stay that way. The promise of fully-reproducible systems is compelling, but the implementation has a ways to go—the Nix language is clunky and poorly-documented (at least it was a few years ago), and trying to shoehorn mainstream packages into the Nix ecosystem is pretty painful (I remember having to track down and port dozens of Python dependencies for some tool I needed). And while the core system is solid, a lot of the auxiliary tooling (like NixOps) just felt half-baked.
(A more mainstream project that shares a lot of conceptual DNA with NixOS is the Bazel build system, although Bazel doesn't go as far as configuring entire operating systems.)
Eventually I decided that I wanted to use my homelab for the purpose of learning technologies that I might actually use professionally, and NixOS sadly doesn't fit in that category so it was time to move on.
V2: OpenStack Madness
I wanted my next homelab iteration to be a bit more akin to what a "real" data center might look like, but I also wanted to keep everything open source (which ruled out options like ESXi). With the benefit of hindsight, the most sensible path would have been to use Proxmox (a homelabbing staple), but for reasons I can't quite remember I decided not to go that route. Instead, after a brief and fruitless detour with oVirt I decided to go "full enterprisey" and deploy OpenStack.
If you haven't heard of OpenStack, it's essentially an open source clone of (some of) AWS, complete with a confusing menagerie of services that integrate together to various extents. (Nova is the EC2 equivalent, Swift is the S3 equivalent, Cinder is the EBS equivalent, and so on.) OpenStack isn't particularly sexy nowadays, but it was extremely hyped at one point and it's still widely used in some industries. My goal was to deploy a Kubernetes cluster on top of OpenStack VMs—more or less how you'd do it with a cloud provider—and deploy most of my applications to Kubernetes (with some extra VMs for applications that aren't easily containerized).
The idea of deploying OpenStack in a homelab was, to be clear, insane. Here's the top comment from a Reddit thread from someone else who succeeded, to give you an idea:
Every part of deploying OpenStack was difficult, beginning with the question of where to even start: OpenStack is designed to be deployed by vendors like Canonical or Red Hat and there isn't really open source "reference deployment" tooling or documentation. To even get the basic components up and running you need MariaDB, RabbitMQ, Redis, and memcached as prerequisites. I ended up using the Kolla project, which uses an unholy combination of Ansible, containers, and Python scripts to do most of the heavy lifting.
After a whole lot of tinkering, I emerged sort of victorious. My VMs were up and running with a working Kubernetes cluster; networking (based on VLANs) and storage (hosted by a VM running FreeNAS) all worked. I used Terraform to manage the OpenStack VMs and Ansible to do most of the VM configuration. I had a mini-cloud in my garage, and there was a lot to like.
But stability was a big problem. When one of my host servers went down unexpectedly I'd often have to run an elaborate recovery process for the MariaDB database. There were bizarre bugs in OpenStack where objects would get stuck in an invalid state, requiring manual database updates. I had circular dependency issues with storage and DNS, which sometimes led to situations so bad that I couldn't even shut down hosts cleanly. And so on.
The OpenStack experiment went on for a couple years,1 and it was nothing if not instructive. Some of the more interesting takeaways that have stuck with me:
- Two servers are worse than one when it comes to availability, at least when there's any kind of state involved. (The OpenStack cluster had two hosts, which was the source of many of my availability woes). Thinking back, this makes a lot of sense from a theoretical perspective: most distributed systems can't tolerate 50% node failure, and two servers means roughly twice as many things to go wrong!
- Circular infrastructure dependencies suck (which seems obvious in retrospect but isn't something I see discussed often). I managed to end up in a lot of situations like "FreeNAS VM depends on Other VM which has NFS backed storage which depends on FreeNAS VM", which were miserable to untangle when something went wrong.
- Virtual Machines Aren't Simple. I often hear things like "Deploying software is easy, just use a VM", but "just" is doing a lot of work in that sentence! Running a VM on a single server isn't too hard, but as soon as networking is involved there's a whole lot of complexity that comes along with it. I really think systems like OpenStack and Kubernetes are complicated because they need to be (of course there's also plenty of accidental complexity to go around), and if "running a VM" seems easy it's usually because thousands of developer hours have been poured into streamlining the experience.
After a while, the constant cycle of downtime and recovery became annoying enough that I was ready to blow it all up and try a new approach.
V3 (You Are Here): Kubernetes All The Things!
After my battles with OpenStack, I had one overarching goal for the next homelab iteration: availability. Specifically, I wanted my lab to be able to tolerate a server going down without catastrophic consequences, and I wanted recovery to be relatively seamless. Also, I didn't want my home internet to get messed up if the homelab cluster went down (which had happened from time to time with the previous setup).
I ended up deploying a bare-metal Kubernetes cluster with three servers. To avoid any possibility of networking circular dependencies, I pulled everything network-related out of the cluster. My router/firewall runs VyOS on a mini-PC, and there are two "net service" Raspberry Pis running DNS servers and some related things like NTP servers. (This is an exception to my "two servers are worse than one" rule because DNS is stateless.)
The biggest roadblock to going "full Kubernetes" was the FreeNAS (now TrueNAS) VM I was using as a storage server. I solved this using Kubevirt, which is a nifty way of running VMs on top of Kubernetes. Kubevirt has been solid, even with exotic requirements like PCI passthrough—here is the YAML definition for the VM if you're curious.
Aside from networking and a smattering of Kubevirt VMs, everything I host runs on Kubernetes (including this blog and my mailing list). The overall architecture looks something like this:
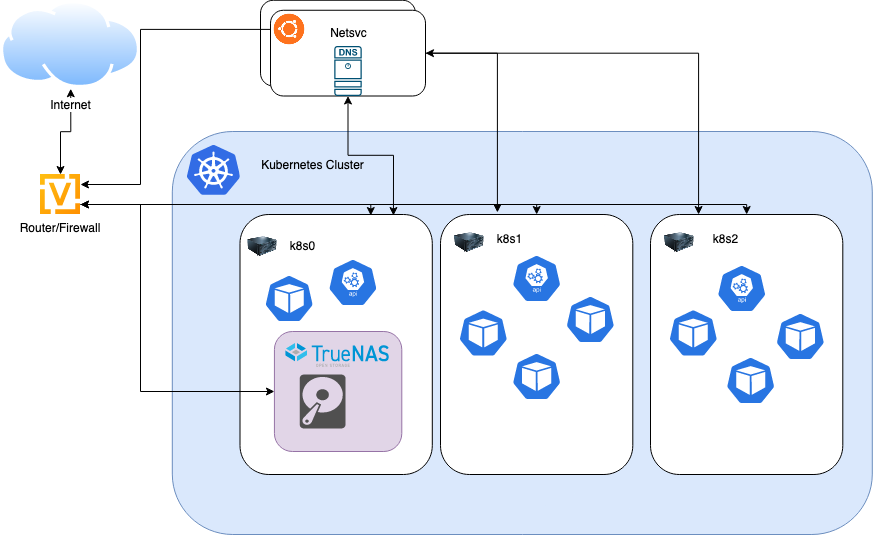
Availability has been much better than the with OpenStack iteration (otherwise I wouldn't be comfortable hosting a blog on it). I still run into the occasional homelab-related uptime challenge (like last week a rat chewed through the fiber internet cable), but recovery is usually pretty painless.
What's Next?
I'm pretty happy with the current setup, so the future will probably be "more of the same". I'll continue deploying applications that seem interesting and probably add some more compute power at some point.
I also want to write some more deep-dives about my homelab and related topics. I've taken on some interesting projects like:
- K8s node provisioning using Terraform and network booting
- Encryption at rest and in transit for pretty much everything (with minimal manual intervention)
- Declarative firewall management with VyOS and Ansible
- Hardware-virtualized VM networking with SR-IOV
- GitOps CD with deterministic Go builds and deployments
Let me know in the comments (self-hosted of course) if there's something you'd
find interesting to cover. (I had to turn off the comments so just drop me a
line.)
Footnotes
There's a quick reference to OpenStack in one of my early blog posts to give a sense of the timeframe.